Types of DSOs in SAP BI and New Terminology
SAP BI Terminology has been changed:
With SAP NetWeaver 7.0, the following terminology changes have been made in the area of Warehouse Management:
The Administrator Workbench is now called Data Warehousing Workbench.
The ODS object is now called DataStore object.
The transactional ODS object is now called DataStore object for direct update.
The transactional InfoCube is now called real-time InfoCube.
The RemoteCube, SAP RemoteCube and virtual InfoCube with services are now referred to as VirtualProviders.
VirtualProvider:
Based on a data transfer process and a DataSource with 3.x InfoSource: A VirtualProvider that allows the definition of queries with direct access to transaction data in other SAP source systems.
Based on a BAPI: A VirtualProvider with data that is processed externally and not in the BW system. The data is read for reporting from an external system, by using a BAPI.
Based on a function module: A VirtualProvider without its own physical data store in the BW system. A user-defined function module is used as a data source.
The monitor is now called the extraction monitor, to distinguish it from the other monitors.
OLAP statistics are now called BI Runtime Statistics.
The reporting authorizations are now called analysis authorizations. We use the term standard authorizations to distinguish authorizations from the standard authorization concept for SAP NetWeaver from the analysis authorizations in BI.
Using the data archiving process, you can archive and store transaction data from InfoCubes and DataStore objects. This function is NOT available for write-optimized DataStore objects.
The data archiving process consists of three main steps:
1.Creating the archive file/near-line object
2.Storing the archive file in an archiving object (ADK-based) or near-line storage
3.Deleting the archived data from the database
A data archiving process is always assigned to one specific InfoProvider and has the same name as this InfoProvider. It can be created retrospectively for an existing InfoProvider that is already filled with data.
In ADK archiving, an archiving object is created for each InfoProvider.
As with the role of the archiving object during ADK archiving, the near-line object addresses the connected near-line storage solution during near-line storage. It is also generated from the data archiving process for an InfoProvider. Near-line objects consist of various near-line segments that reflect different views of the respective InfoProviders and can also reflect the different versions of an InfoProvider.
Semantic Keys & Semantic Groups:
Semantic Keys can be defined as standard keys in further target Data Store. The purpose of the semantic key is to identify error in the incoming records or duplicate records. All subsequent data records with same key are written to error stack along with the incorrect data records. These are not updated to data targets; these are updated to error stack. A maximum of 16 key fields and 749 data fields are permitted. Semantic Keys protect the data quality. Semantic keys won’t appear in database level. In order to process error records or duplicate records, you must have to define Semantic group in DTP (data transfer process) that is used to define a key for evaluation. If you assume that there are no incoming duplicates or error records, there is no need to define semantic group, it’s not mandatory.
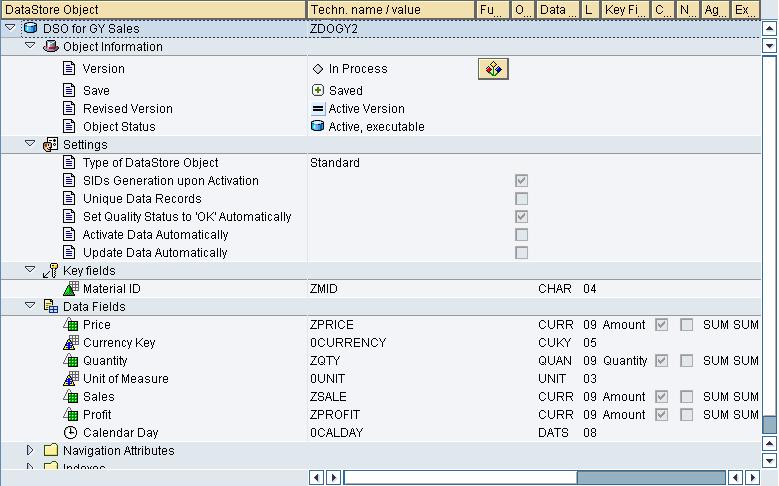
1.Standard DSO : -

2. Write Optimized DSO:-

Write-Optimized DSO - Semantic Keys:
Semantic Key identifies error in incoming records or Duplicate records.
Semantic Keys protects Data Quality such that all subsequent Records with same key are written into error stack along with incorrect Data Records.
To process the error records or duplicate records, Semantic Group is defined in DTP.
Note: if we are sure there are no incoming duplicate or error records, Semantic Groups need not be defined.
Since write-optimized DataStore objects do not have a change log, the system does not create delta (in the sense of a before image and an after image).
When Write Optimized DSO is Recommended?
For faster data loads, DSOs can be configured to be Write optimized
When the access to source system is for a small duration.
It can be used as a first staging layer.
In cases where delta in DataSource is not enabled, we first load data into Write Optimized DSO and then delta load can be done to Standard DSO.
When we need to load large volume of data into Info Providers, then WO DSO helps in executing complex transformations.
Write Optimized DSO can be used to fetch history at request level, instead of going to PSA archive.
3. DSO for Direct Update: -

Info @ a Glance: The DataStore object for direct update differs from the standard DataStore object in terms of how the data is processed. In a standard DataStore object, data is stored in different versions (active, delta, modified), whereas a DataStore object for direct update contains data in a single version. Therefore, data is stored in precisely the same form in which it was written to the DataStore object for direct update by the application. In the BI system, you can use a DataStore object for direct update as a data target for an analysis process. More information: Analysis Process Designer(APD).
The DataStore object for direct update is also required by diverse applications, such as SAP Strategic Enterprise Management (SEM) for example, as well as other external applications.
Just click on Change/Create ->

With SAP NetWeaver 7.0, the following terminology changes have been made in the area of Warehouse Management:
The Administrator Workbench is now called Data Warehousing Workbench.
The ODS object is now called DataStore object.
The transactional ODS object is now called DataStore object for direct update.
The transactional InfoCube is now called real-time InfoCube.
The RemoteCube, SAP RemoteCube and virtual InfoCube with services are now referred to as VirtualProviders.
VirtualProvider:
Based on a data transfer process and a DataSource with 3.x InfoSource: A VirtualProvider that allows the definition of queries with direct access to transaction data in other SAP source systems.
Based on a BAPI: A VirtualProvider with data that is processed externally and not in the BW system. The data is read for reporting from an external system, by using a BAPI.
Based on a function module: A VirtualProvider without its own physical data store in the BW system. A user-defined function module is used as a data source.
The monitor is now called the extraction monitor, to distinguish it from the other monitors.
OLAP statistics are now called BI Runtime Statistics.
The reporting authorizations are now called analysis authorizations. We use the term standard authorizations to distinguish authorizations from the standard authorization concept for SAP NetWeaver from the analysis authorizations in BI.
Using the data archiving process, you can archive and store transaction data from InfoCubes and DataStore objects. This function is NOT available for write-optimized DataStore objects.
The data archiving process consists of three main steps:
1.Creating the archive file/near-line object
2.Storing the archive file in an archiving object (ADK-based) or near-line storage
3.Deleting the archived data from the database
A data archiving process is always assigned to one specific InfoProvider and has the same name as this InfoProvider. It can be created retrospectively for an existing InfoProvider that is already filled with data.
In ADK archiving, an archiving object is created for each InfoProvider.
As with the role of the archiving object during ADK archiving, the near-line object addresses the connected near-line storage solution during near-line storage. It is also generated from the data archiving process for an InfoProvider. Near-line objects consist of various near-line segments that reflect different views of the respective InfoProviders and can also reflect the different versions of an InfoProvider.
Semantic Keys & Semantic Groups:
Semantic Keys can be defined as standard keys in further target Data Store. The purpose of the semantic key is to identify error in the incoming records or duplicate records. All subsequent data records with same key are written to error stack along with the incorrect data records. These are not updated to data targets; these are updated to error stack. A maximum of 16 key fields and 749 data fields are permitted. Semantic Keys protect the data quality. Semantic keys won’t appear in database level. In order to process error records or duplicate records, you must have to define Semantic group in DTP (data transfer process) that is used to define a key for evaluation. If you assume that there are no incoming duplicates or error records, there is no need to define semantic group, it’s not mandatory.
Types of DataStore Objects (DSOs) : -
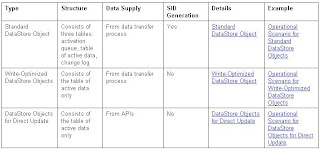

1.Standard DSO : -
2. Write Optimized DSO:-

Write-Optimized DSO - Semantic Keys:
Semantic Key identifies error in incoming records or Duplicate records.
Semantic Keys protects Data Quality such that all subsequent Records with same key are written into error stack along with incorrect Data Records.
To process the error records or duplicate records, Semantic Group is defined in DTP.
Note: if we are sure there are no incoming duplicate or error records, Semantic Groups need not be defined.
Since write-optimized DataStore objects do not have a change log, the system does not create delta (in the sense of a before image and an after image).
When Write Optimized DSO is Recommended?
For faster data loads, DSOs can be configured to be Write optimized
When the access to source system is for a small duration.
It can be used as a first staging layer.
In cases where delta in DataSource is not enabled, we first load data into Write Optimized DSO and then delta load can be done to Standard DSO.
When we need to load large volume of data into Info Providers, then WO DSO helps in executing complex transformations.
Write Optimized DSO can be used to fetch history at request level, instead of going to PSA archive.
3. DSO for Direct Update: -

Info @ a Glance: The DataStore object for direct update differs from the standard DataStore object in terms of how the data is processed. In a standard DataStore object, data is stored in different versions (active, delta, modified), whereas a DataStore object for direct update contains data in a single version. Therefore, data is stored in precisely the same form in which it was written to the DataStore object for direct update by the application. In the BI system, you can use a DataStore object for direct update as a data target for an analysis process. More information: Analysis Process Designer(APD).
The DataStore object for direct update is also required by diverse applications, such as SAP Strategic Enterprise Management (SEM) for example, as well as other external applications.
The Procedure to create Direct Update DSO is as usual as Standard DSO, but Under Settings of DSO creation screen -->Type of DataStore Object --> Direct Update.
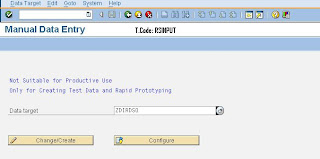
If you want to entere data manually. Go to T.code: RSINPUT. It Just look like this
Note: Not Suitable for Productive Use and Only for creating Test Data and Rapid Prototyping.

Just click on Change/Create ->
It allows to enter records (Entries) and displays on Top.
The DataStore object for direct update is available as an InfoProvider in BEx Query Designer and can be used for analysis purposes.
The DataStore object for direct update is available as an InfoProvider in BEx Query Designer and can be used for analysis purposes.

{kind=link}
Comments
Great Blog with a lot of Great Information....
CheErS....
Hav Fun....
Thanks for Maintaining this Blog.
Cheers.
I am facing one error in Sap BI 7.0 Infopackage level when loading CSV file .
Error: Data sorce 'DS_CUST' not available in source system of Active version 'A' and 'space' 00H not allowed in escape entry.
Please guide me.
Regards,
subhendu
subhendumohanty5@gmail.com